
Action data reference
When performing active selection in either the model editor or the Python SDK, a number of key data elements are returned that reveals the internals of the Genius agent's decision-making process. This reference page provides more detail on each of these components and their purpose. Looking into the agent in this way makes Genius agents more explainable and interpretable. Agents are not black-boxes and we can examine aspects of their internal calculations to understand how they came to their decisions.
Belief state
The belief_state JSON key contains the agent's probability distribution over all state factors in the model. In other words, having seen some data, the agent performs the process of perception to determine the most likely state. Since a POMDP model can have more than one type of state (known as a state factor) the probability distribution over each of these types of states is returned.
Each state factor under belief_state consists of:
probabilities: The probability distribution calculated by the agent for over all categories in the state factor.elements: The category names for the state factor.
Example: In the multi-armed bandit example, there are two state factors: choice and context. The belief_state has the following form:
'belief_state': {
'choice_names': {
'probabilities': [1.0, 9.999999999999931e-33, 9.999999999999931e-33, 9.999999999999931e-33],
'elements': ['Start', 'Hint', 'Left-Arm', 'Right-Arm']
},
'context_names': {
'probabilities': [0.5, 0.5],
'elements': ['Left-Better', 'Right-Better']
}This shows the probability for each element under each of the different state factors.
Policy belief
Active inference agents perform decision-making by exhaustively computing all possible sequences of actions they could take. For example, in the multi-armed bandit example, there are 4 possible actions: Move-start, Get-hint, Play-left, and Play-right. A policy length of 2 was chosen which means there are sixteen possible sequences of length 2 actions the agent could take:
These actions sequences are known as policies. Active inference agents rank policies based on a calculation known as expected free energy (EFE). EFE is calculated across all time steps (actions) in a policy so each of the above policies will receive a unique EFE calculation. The resulting EFE calculation is then converted into a probability distribution as captured in the policy_belief JSON key (see EFE components section for more detail). For the multi-armed bandit example, policy_belief can be plotted:
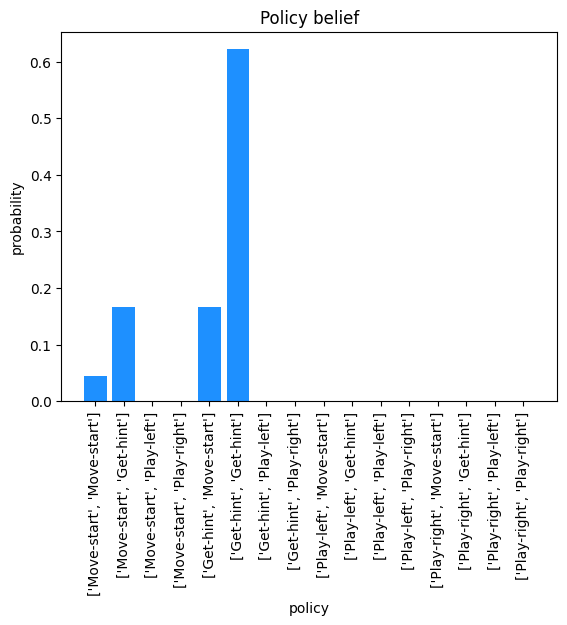
As we can see, the 6th policy has the highest probability of being chosen at this time step. This demonstrates how the agent comes to its decision.
EFE components
Expected free energy (EFE) can be broken down into three main components:
Expected utility - Calculates the extent to which pursuing the policy under consideration would lead to the agent's goals as encoded by its prior preferences (reward-seeking behavior)
State information gain - The amount of information the agent would get from exploring its environment to learn more about how states relate to observations (curiosity/exploratory behavior)
Parameter information gain - The amount of information the agent would get from exploring its environment to learn more about the probabilities encoded in each factor (likelihood or state-transition)
Total EFE - The total EFE over all policies. As explained further below, this is equal to expected utility + state information gain - parameter information gain terms.
These three components are used to calculate EFE. By examining their values we can better understand what drove the agent to select the action that it did. We can see if the agent valued reward-seeking behavior or exploratory behavior in the current action selection.
Mathematically, EFE represents the following calculation:
where:
Gπ
Expected free energy for a policy, π
DKL
KL divergence (information gain)
Q
An approximate posterior distribution
oτ
An observation at time step τ
π
A particular policy under consideration
P˘(oτ)
An agent's biased model of observations it "desires" to receive or more simply the agent's "preferences"
sτ
States at time step τ
θ
Model parameter or factor probabilities for the likelihood and/or state-transition
or in words:
The efe_components JSON key provides the breakdown of the agent's internal calculation for these elements alongside the total:
expected_utility: The expected utility contribution to EFE for each policy.states_info_gain: The state information gain contribution to EFE for each policy.param_info_gain_A: The parameter information gain of the likelihood factor for each policy.param_info_gain_B: The parameter information gain of the state-transition factor for each policy.total_efe: The total expected free energy calculated from the above four components.
In order for an active inference agent to decide upon the correct course of action it must calculate the expected free energy for each possible sequence of actions (policies). Expected free energy is measured in units of nats which is used in information theory. These values are converted into a valid probability distribution through softmax normalization of the negative EFE for each policy, which squashes all the negative EFE measurements between zero and one.
Action data
When calculating EFE, the active inference agent took the sum of EFE over each action it could perform at each future time step. The action_data JSON key unravels this sum so we can see the EFE contribution calculated for the most immediate action rather than the sum over the whole sequence of actions in the policy. For example, if the selected_action is 1 in the multi-armed bandit example, then the agent has chosen to evaluate the EFE for the Get-hint action. The action_data JSON key lists the following for this action:
selected_action: The index of the sampled action corresponding to the action/control variable.efe: The expected free energy for taken the chosen action.expected_utility: The expected utility for this action.states_info_gain: The state information gain for this action.param_info_gain_A: The parameter information gain of the likelihood factor for this action.param_info_gain_B: The parameter information gain of the state-transition factor for this action.action_value: The contribution of this action to the finalpolicy_belieffor the expected utility component (utility_contribution), the information gain component (infogain_contribution) and the total (inverse_efe).
Updated VFG
Since POMDP models operate online and sequentially as data arrives, they constantly adjust hidden state believes in response to this new data. Thus after each timestep, having taken an action, the VFG needs to be upated with the newly calculated hidden state inference probabilities for the initial state priors. This field of the action data response stores this updated VFG so it can be used to update the Genius agent's model.
Last updated